kaiokendev
Extending Context is Hard…but not Impossible†
On the surface, it should be an easy task.
I was working on this write up while I was working through methods to finetune the pre-trained model for longer sequence length. In this case, the pre-trained model is LLaMa, with a pre-training sequence length of 2048. Naively fine-tuning the model on long sequences never seemed to work, but I felt it must be possible, so I stubbornly pushed through it. Now, there is a way to extend context with just 1 line of code, and it is getting a lot of attention. Unfortunately, there is also a lot of misconceptions on what is happening, why it works, and why it is so simple. I see a lot of people calling it a “hack” or a “trick” simply because it is only 1 line of code. To that end, I decided to publish the write up even though it is incomplete, to hopefully give my brain dump of what I was thinking through and clarify what is happening.
In other words, expect mistakes lol
Concurrent work
EDIT: 6/27/2023 I was just notified that Meta themselves have concurrently discovered the same interpolation property via Chen et al. 2023. I heavily recommend reading their paper; a lot of their findings parallel my own, but they provide extensive experimentation and additional reasoning behind why it works. Yes, I’m equally surprised it was being discovered in two different places at the same time!
The paper: https://arxiv.org/pdf/2306.15595.pdf
The Problem
So why is it so hard for the model to generalize its learnings to extended sequence length? Let’s look at a few papers that also observed this behavior:
- Anil et al. 2022 observe that length extrapolation fails in large part due to the presence of “distracting tokens” in the input during the PARITY task. I want to highlight the below from their Appendix F:
Our analysis in Section 4 indicates that length generalization pathologies persist even when we use the padded scratchpad strategy that makes sure that it’s not untrained position encodings and/or the EOS token prediction that causes the aforementioned pathologies. This points to the fact that the transformer doesn’t learn to attend to the “right” section of the input and scratchpad that implements the sequential strategy that generalizes to longer lengths — it’s thrown off by distractor tokens in the input and/or the preceding scratchpad targets. The distractor tokens at which section of the transformer context window (input or scratchpad) contribute more to the performance deterioration? If we remove all the distractor tokens, can we achieve perfect length generalization? […] We conclude from this experiment that:
- Removing all distractor tokens does result in perfect length generalization.
- The distracting input tokens are hurt length generalization performance more.
- Chi et al. 2022 observes that bias terms in positional encoding (such as with ALiBi) replicate the effect of windowed attention by decaying token inter-dependency on long-range receptive fields (the tokens only focus on the tokens closest to them.) They apply this to create Sandwich to alleviate this effect.
- Tao et al. 2023 somewhat follow a similar path to Anil et al. with their observation that during long sequences, rear position embeddings are updated much fewer times than front position embeddings. However, they take a different approach by adding random padding to the front patch of the sequence; they observe (IMO, a marginal) ~+0.2% to ~+0.8% accuracy increase on F1 for BERT variations. This is even addressed in Anil et al.,
LaMDA models use T5 position biases to handle position information. If the network is only trained with short instances, position biases that handle longer positional distances might not be trained, explaining poor length generalization.
[…] We tested the extent to which these effects can explain lack of length generalization […]
While this intervention helps, the trained models still display significant length generalization issues
- Liu et al. 2023 also observe that Transformer accuracy on flip-flop task breaks down on long sequences. Specifically, they note in Appendix B.5:
The failure could be attributed to multiple factors; we will explore one aspect related to attention patterns, demonstrated with a 1-layer 1-head Transformers with linear position encoding, on a length-834 sequence with 2 writes. As shown in Figure 12, the attentions for positions early in the sequence correctly attend to the most recent write. However, attention starts to “drift” as we move to later positions, and the positions at the end of the sequence attend entirely to the recent read tokens, which contains no information for solving the task. This may be because the attention weights are affected too much by the position encodings, as discussed in Proposition 4.
Proposition 4. Consider linear positional encoding, i.e. pi = i/C for some (large) constant C. Then, perfect length generalization to arbitrary length requires:
W_Qp^T * W_Kp = 0.
Silver Linings
Now that we have a better sense of the problem, which seems to be the attention mechanism destabilizing in the case of long sequences due to an imbalance of attended tokens (either skewed to the front or the back), let’s look at some proposed ways to remedy the effect.
- Bueno et al. 2022 demonstrate that pre-trained models length extrapolate well when prompted using few-shot chain-of-thought reasoning and marker tokens. Specifically, the act of summarizing the necessary steps to complete the task while sequentially marking completed tasks “teaches” the model how to length extrapolate in an in-context setting.
We also interleave the tokens ic and oc with markup tokens that help the model to precisely identify the tokens in the input and output sequences (see Figure 1-(b) for an example). These tokens support the model in three ways: 1) They act as a form of working memory to indicate progress being made. 2) They act as sub-prompt anchors to inform the start of a known pattern. 3) They implicitly model a stopping condition should a certain amount of progress be reached.
- Anil et al. 2022 implies that length generalization/extrapolation is a learned ability, not something that depends entirely on model architecture:
We show that in the in-context learning regime, use of a scratchpad shows a qualitatively different behavior and significantly alleviates the decay of performance on longer problems. This capability is significant, as it implies that for LLMs, there are certain skills, like length generalization, that can be learned through in-context learning rather than through finetuning even in the presence of infinite data. This is in stark contrast to the common norms of machine learning (Section 5).
However, note that they caveat this with the following (Appendix E):
In Section 5.1, we hypothesized that few-shot finetuning only leads to significant improvements in length generalization performance if the non-finetuned performance on the same task already at a nontrivial level. To provide a sanity check for this, we ran few-shot finetuning using an alternative prompt style for the coin-flip task that yields poor non-finetuned performance. As can be seen in Figure 14, the few-shot finetuned performance shows significant length generalization pathologies
In other words, the performance improves, but it is not a silver bullet to enable extrapolation, especially for tasks in which the model was already performing poorly without fine-tuning. The only method which seemed to improve performance consistently, is the removal of the distracting tokens:
- Mohtashami et al. 2023 demonstrates they are able to fine-tune LLaMa 7B to achieve perfect retrieval over a 32K token window by introducing landmark tokens combined with a windowed-attention (in the form of a blockwise computation). LLaMa has a pre-trained context length of 2048 using rotary position encoding.
We replace the softmax function after computing the attention scores with Grouped Softmax. For each block, we put its regular tokens in a separate group, ensuring that all regular tokens within the same block share the same group, while tokens outside the block are assigned to different groups. When computing the attention weights for the i-th token, landmark tokens for other blocks are placed in the same group as the i-th token. The landmark token for the i-token’s block is ignored when computing the attention weights for the i-th token. In other words, the landmark token for each block is only used by tokens in other blocks. This is intuitive as the landmark token should only be accessed when tokens in other blocks require to retrieve information from the landmark’s corresponding block
Importantly, their windowing approach differs from a standard block-limited approach, as the introduction of the landmark gates means that each landmark has access to all other landmarks, which in turn have access to all of the tokens in their own blocks. It moreso resembles a mixture of global + block diagonal attention. Additionally, the authors introduce a modification to the positional encoding by adding a random jump to the position index for each block’s tokens based on their landmark token’s position:
Data augmentation has been used in various settings to allow the model to generalize to additional settings such as reflections of the same image [20]. We propose to apply augmentation on positional information in Transformers to allow them to extrapolate to longer contexts. In the standard positional encoding, the positions are increased by one at each token, leading to the tokens being assigned positions 1 to ℓseq where T is the length of the input. In particular, instead of assigning positions from 1 to T, where T is the length of the input, we propose to increase the positions of all subsequent tokens by a random integer between 1 and pjump after each landmark token. We refer to these increases as making positional jumps. When pjump = 1, no augmentation is applied and the standard positions are recovered.
[…]
We can see that using the augmentation, the model becomes capable of utilizing longer contexts. This is evident by the fact that we observe reduction in perplexity as we increase context lengths until 1400 tokens which is close to the theoretical estimate of model’s extrapolation capacity. In contrast, the decreasing trend stops for the standard model before reaching 1024 tokens
In a way, it somewhat resembles the random padding from Tao et al.
Intermission
Before we move on, let’s address the elephant in the room – why are we talking about length extrapolation in the context of extending the context length during fine-tuning? To answer that question, we first have to answer the question: Why is it easy to pre-train on sequence length L, but it is hard to naively fine-tune for sequence length 2L? In fact, we can view fine-tuning on extended context length as a length extrapolation problem.
While Anil et al. control for the effect of the EOS token on the skewed attention distribution, their approach relied on a fine-tuned LaMDA model with padding.
We padded both the input bit-strings and the scratchpad content with dummy padding tokens to make the token count the same. We also augmented the input and scratchpad targets with the same number of padding tokens on the left and right so that the relevant bit to attend to when executing the sequential scratchpad strategy corresponds to the same T5 position bias bin.
Is it really the case that this is sufficient to control for the effect of the EOS token on a pre-trained model?
Potential Solutions
Change the Attention Calculation
Chiang & Cholak 2022 propose a simple contribution to improved length generalization – scaling the attention by log(n), where n is the length of the input sequence. (I believe the base should be the pre-training length?)
As predicted by Hahn’s lemma, our constructed transformers have cross-entropy that approaches 1 bit (that is, just barely better than random guessing) as input length increases. But we show that by adding layer normalization, the cross-entropy can be made arbitrarily close to zero, independent of string length (§4). In practice, we find, like Bhattamishra et al. (2020a), that transformers cannot learn PARITY. Perhaps more surprisingly, when learning FIRST, transformers can have difficulty generalizing from shorter strings to longer strings. Although this is not a logical consequence of Hahn’s lemma, it is a consequence of the behavior that Hahn’s lemma predicts. Fortunately, this problem can be fixed with a simple modification, multiplying attention logits by log 𝑛. This modification also improves length generalization in machine translation (§5).
Shen et al. 2023 propose to replace the standard softmax in the attention equation with ReLU, which should improve stabilization on outputs for long sequence lengths.
They find that softmax performs worse than ReLU on long sequences due to the destabilization of scores that occur with a sufficiently large matrix:
By changing the total number of key-value slots, we find that ReLU performs better than Softmax when the number of slots is larger. We explore the reason by calculating the ratio of top scores among all activations and find that the activation weights are highly centralized in a small number of slots, thus insufficient to utilize the context information of other slots, while ReLU is able to alleviate this problem. Given the superior performance of ReLU when scaling to a large number of value slots, we then explore how ReLU performs on SAN where Softmax may have a trouble modeling long-sequences (Sun et al., 2022). Unfortunately, directly alternating Softmax to ReLU does not converge. With theoretical and experimental analysis, we find that the variance of SAN results with ReLU activation grows with the length of the input sequence, and the dynamic variance will lead to an unstable training process. Therefore, a variance reduction factor and regularization loss functions are introduced to solve this problem. As a result, we make it possible to utilize ReLU on self-attention, which performs better than Softmax when dealing with long input sequences.
Random Positional Encoding
I stumbled on this paper from Ruoss et al. 2023, in which they claim they are able to boost extrapolation capability ranging from +10% to +50% using a new encoding scheme. Funny enough, I had seen this paper before, at least, the anonymized version of it, but I think seeing the words “randomized positional encoding scheme” I ignored it, thinking “I need something compatible with RoPE!”
Transformers have impressive generalization capabilities on tasks with a fixed context length. However, they fail to generalize to sequences of arbitrary length, even for seemingly simple tasks such as duplicating a string. Moreover, simply training on longer sequences is inefficient due to the quadratic computation complexity of the global attention mechanism. In this work, we demonstrate that this failure mode is linked to positional encodings being out-of-distribution for longer sequences (even for relative encodings) and introduce a novel family of positional encodings that can overcome this problem. Concretely, our randomized positional encoding scheme simulates the positions of longer sequences and randomly selects an ordered subset to fit the sequence’s length. Our large-scale empirical evaluation of 6000 models across 15 algorithmic reasoning tasks shows that our method allows Transformers to generalize to sequences of unseen length (increasing test accuracy by 12.0% on average).
As of this writing, the code mentioned in the paper is not available at the provided link, https://github.com/deepmind/randomized_positional_encodings. (As of 6/23/2023, the code is there) It sounds like an entirely new scheme. However, when we take a closer look, the technique is trivial, so you can implement it in a few lines of code:
We assume that each training step will perform a step of loss minimization on a batch of data of fixed size. Let
U(S)denote the discrete uniform distribution over setS, and letPk := {S ⊆ {1, . . . , L}| |S| =k}. For each training step, we first sample a random lengthn ∼ U({1, . . . , N})(following Delétang et al., 2023) and then a random set of indicesI ∼ U(Pn). We then sortIin ascending order, such thatI = {i1, . . . , in} for i1 < i2 < · · · < in, noting thatIis sampled without replacement. Finally, we compute our randomized positional encoding for token1 ≤ j ≤ NasRPE(j, ·) := PE(ij , ·). At test time, when processing a sequence of lengthM > N, we use the same procedure but for all token positions1 ≤ j ≤ M. The intuition behind our method is to preserve the known good properties of relative encoding but in a way that is independent of the maximum training length N and thus allows generalization to longer sequences at test time.[…]
When applying our randomized positional encoding scheme, we subsample the extended positions only once per batch and not individually for every sequence. For the sin / cos (Vaswani et al., 2017), learned (Gehring et al., 2017), and RoPE encodings (Su et al., 2021), we apply our method as described above, i.e., we directly replace the original token positions with their sampled counterpart.
For reference, here is my naive implementation for RoPE. While the loss converged, I did not notice any improvements to the behavior, but maybe it is wrong:
def get_random_position_ids(n=2048, max=8192, device="cpu"):
positions = torch.randperm(max)[:n].sort().values.unsqueeze(0)
positions = positions.to(device=device)
return positions
def apply_rotary_pos_emb(q, k, q_freqs, k_freqs, position_ids=None):
...
positions = get_random_position_ids(
n=position_ids.shape[-1], device=position_ids.device
)
...
Like I said: a few lines of code.
Recall the solution proposed by Tao et al. that yielded meager gains for BERT-derived models?
As shown in our pilot study, when we train a model on instances of short contexts , embeddings at the front positions can be updated much more times than those at rear positions. Therefore, it is intuitive to balance the updating times over the whole range of positions, i.e., to reduce updating times of front position embeddings and to reallocate more updating to rear ones.
[…]
Recall that when fine-tuning a PLM for extractive QA, we only update the position embeddings of non-padding tokens. Since padding tokens are always at the rear positions of whole input sequence, these rear position embeddings are often ignored in the scheme of absolute position embedding. If padding tokens can be randomly placed in the whole sequence during fine-tuning, we can expect that every position embedding has almost equal chance to be updated or ignored. However, if we insert padding tokens into question or context, it will change the positional relationships of non-padding tokens, which might hurt model performance. Therefore, we should preserve the question tokens and the context tokens as contiguous sequences. Specially, during fine-tuning, we propose to move a random number of padding tokens to the front of the input sequence, as shown in Figure 2. Then non-padding tokens will be pushed towards the end of input sequence, so that the rear position embeddings can be updated.
We also saw a reference to jumping positional encodings yielding significant improvements in Mohtashami et al. Additionally, recall that Liu et al. also observed the same effect, and a similar solution was proposed:
In this section, we investigate various approaches towards eliminating the long tail of reasoning errors exhibited by Transformer FFLMs. We select the 19M-parameter model (which has L = 6 layers, d = 512 embedding dimensions, and H = 8 heads) from Section 4 as a canonical baseline, and conduct precise evaluations of various direct and indirect interventions.
[…]
Ideal solution: improving data coverage. Prior work has made clear that data significantly impacts the performance (Schuhmann et al., 2022; Eldan and Li, 2023). Hence, we begin by examining what is perhaps the most obvious solution: removing the need for out-of-distribution extrapolation, by training directly on more diverse examples. Indeed, we verify that this works near-perfectly:
Training on rare sequences works best, by a wide margin. By training on a uniform mixture of FFL distributions with pi = {0.9, 0.98, 0.1}, the baseline architecture reliably converges to solutions with significantly fewer errors on each of these 3 distributions (teal violins in Figure 4). In 6 out of 25 runs, we did not detect a single error.
This should not be surprising, in light of the realizability of flip-flops by self-attention (and, more generally, the existence of shortcuts functionally identical to RNNs (Liu et al., 2023)), and corroborates similar conclusions from (Zhang et al., 2021).
In effect, the approach by Ruoss et al. is sort of like a generalized form of random padding – by dilating the sequence over the desired context length size, they effectively pad the input sequence, but only during the position encoding step. I don’t think it is a coincedence that padding to the unseen positions is a recurring theme in the potential solutions. Maybe Tao et al. had the correct intuition after all, although their implementation was sidestepped somewhat because they are constrained by the absolute encoding scheme of BERT models. I think a better name for the above implementation would have been “dilated positional encoding”, but that’s just me.
Shifted Positional Encodings
Inspired by the above, I wondered - “Since this works so well, can’t we just shift the tokens progressively along the desired length during the encoding step?” As in,
def shifted_positions(n=3072, min=6144, max=8192, offset=3072, device="cpu"):
positions = (torch.arange(max) + offset)[:n].sort().values.unsqueeze(0)
positions = positions.to(device=device)
return positions
It turns out this also failed to extrapolate for me despite the loss converging. Again, I might have broken my training code somehow, since it feels like it should work.
EDIT (6/25/2023): Kiyono et al. 2021 proposed a similar scheme for absolute position embedding and show that it outperforms APE on long sequences.
Log-n Scaling
I tried with log-n scaling. After implementing log(n) scaling, the length generalization improved dramatically, but it still was not perfect. At least, this seems to imply the score destablization contributes greatly. The following is an attempted story continuation with 2800 tokens of context on a LLaMa 13B LoRA (rank 16) trained on ~1000 samples (~500 3072-token samples). The model generated ~+320 tokens:
As they waited patiently watched the sunset, the skyline.
Justin's attention was drawn to the beauty of the world, and the vast landscape around him. He could hardly believe that the scene was real. In fact, the most spectacular viewscape in the natural wonders of nature.
After seeing the film, one will hope to discover the answer to the following questions that remain unanswered: Why does it take so long to discover the truth about the universe? Where exactly is located in space? Orbital Systems International Space Programming & Development Center. 204589137. 12. 2.
During the event, the conference focused primarily on the development of technology, space, the future of technological developments, and potential applications. Technology Conferences. Journal papers presented at AACMIPCC, Cognitive Science Conference Abstract Research Paper (PDF)
Abstract Measurement Design: Task Force Analysis.
In addition to the research literature, psychology, social science, sociology, cognition & motivation, learning, behavioral processes & performance, sensory responses. Journal Articles & Technical Issues.
Journal.
Cognitive Ability & Learning & Performance.
Conference Characteristics & Performance. Journalism. The purposeful.
Journalism. Journal Article 1. The journal article examines the impact of the field of psychology & society. The paper is designed using the following procedures to investigate & examine the effects of psychology & Neuroscience.
The Psychology. 1. 1. 2. Theories.
Ps & Performance.
Performance & Societal Behavior.
This snippet focused on the relationship between parents and children and teachers. The results showed significant changes in parental relationships among parents and families and professionals.
The Journal of The Journal of the Yearbook of Life Sciences: Journal of Education, Pedagree, Mental Health & Wellness & Self-Center: Parent education programs and teaching strategies, and practices. Journal & Education: Theory & Teaching & Practices & Practice.
Journalists: Social & Professional Training Programmes. Journal of Education & Educational Studies: Critics. The Journal of Psychology.
Despite the factual points made above the previous years, this week has been published by the National Publishing Society Magazine & Books & Magazine & Publications & Journament & Publications & Publications & Biblians & Publications. 19. The Journal & Publications & Publishings & Applications. 20 1. The publication. The Journal of the year.
She is based on the. 1. 2. The Journal & 19, Journal. The 1. The 1.
The Journal 19, 19, 1. 1. The Journal 1. 1. Journal &1. Journal 1. 1. 1. 1. 1. The Journal. The 1. The 1. 1. 1. 1. 19. The 1. 1. The 19. 1. 19. 19. 1.
We can see the beginnings of proper extrapolation here, as without the changes, the model breaks down rapidly after just 2200 tokens, and after 2600 tokens it is not usually possible to string together complete sentences. It may be the fact that there is not enough data at the extended lengths to teach the model how to properly handle those positions. It may also be due to using LoRA, as the original model weights are still frozen and may be conflicting? At the same time, we would like the model to learn how to extrapolate past the training data positions, and so we would like to be able to train with data that is smaller than 3072 tokens. But this absolutely confirms that the model is at least capable of going beyond 2048 without having to re-train from scratch.
I then try again but this time adding shifted positional encodings over a window of 8192, with token cutoff 2048 and offset increased by 2048 per batch before rolling back to 0. At first, the model converges properly, and up to position 6143 the loss drops to 2.378 (from 4.36 at the start in offset 0). However, in the final position bucket (6144 ~ 8191), the loss begins to explode (going up to 49155). It is hard to tell what the problem might be – maybe the model is not able to capture the dependencies up to 8192 through the LoRA training using the scaling alone; Possibly, it can be issues with AdamW, or a different learning rate schedule needs to be used. However, after some time the loss began to drop back down to 19232. I continue the training resuming from the checkpoint but fix the positions to the last bucket to try and see if we can converge, but to no avail.
I repeated the training with no scaling (to see if simply shifting the positions is enough), but experienced the same issue – no convergence.
Remember the Basics
All I could think after doing all this reading and experiments is that the world must be upside down. There does not seem to be any reason why the pre-trained model cannot extrapolate, and yet it can’t. I thought, maybe, I’m thinking about it the wrong way – the pre-trained model should be capable of perfect extrapolation, but something is preventing it from doing so, or supressing the behavior – something outside of the positional encoding, something outside of the attention itself, and probably something outside of the model architecture. Maybe a floating-point error somewhere that has gone unnoticed? Maybe it is the design of the transformer itself that we need to change, and just switch everything back to RNN?
In all of this, I realized I never tested the degenerate case: remove the attention values entirely; Nuke the attention map?
Clamping and Masking
First, I constructed the sliding window attention mask. Sliding window attention was introduced in Longformer and looks something like this:
0 x x x x x
0 0 x x x x
x 0 0 x x x
x x 0 0 x x
x x x 0 0 x
x x x x 0 0
In other words, each token can only look at the previous w tokens where w is the window size, in this case w = 2. Now, I know window attention must work, because it works in Longformer, Landmark Attention, BigBird, and it worked for XPos (in the form of blockwise causal attention, but the effect is roughly related in that they are all local attention schemes, just that their windows are more exotic).
And yet, if we take an off-the-shelf model, it will produce coherently right up until the pre-trained context limit, then the coherency falls off a cliff. This makes no sense whatsoever. If the model can only see the previous 3 or 30 tokens, and it can produce coherent text when given 30 tokens, why in the world is it failing when we use the mask which should achieve the same effect?
I additionally tried clamping the attention logits, such that any values lower than a certain threshold would disappear. Alas, no shot.
After a day or so of mulling it over and digging even deeper, I stumbled on Ofir Press’ oral presentation of ALiBi. Suddenly, I had a brain blast, and everything began to make sense.
A Bigger Problem
Put simply, Press’ hunch is that the pre-trained model has not learned how to gauge position based on the relative distance or the rotational factors, contrary to what we might have hoped. Instead, it does what transformers do best: it learned a shortcut by memorizing the tokens and their positional scaling factors.
Let’s take a simple example – LLaMa 13B, with no additional fine-tuning. We change the apply_rotary_pos_emb to loop the positions around after crossing 2048:
position_ids = position_ids % 2048
All of a sudden, with that one line of code change, the model is remaining coherent well beyond 3000 tokens! In fact, I noticed that the closer the input sequence was to 2048, the more coherent the output became – complete gibberish when the modulo was 0, but perfect extrapolation at every 2048 tokens.
I then tried block repeated positions – repeating the chosen frequency for a block of positions. For example, instead of using positions [1, 2, 3, 4, 5, 6, 7, 8, 9 … L] where L is the pre-trained sequence length, we use [1, 1, 1, 1, 2, 2, 2, 2,… L, L, L, L]. This worked even better than the modulo. Intuitively, it’s very simple: the model knows all positions between [0, L], so it will hopefully learn better if we stick to that range. From this, I merely changed it to one-line which only affects the frequency steps:
t *= 1/4
1/4 was chosen since I noticed OpenAI keeps upping their context sizes by a factor of 4. Not saying this is how they achieved their increased contexts, but it’s where I got the number from. Fine-tuning models on this adjusted frequency scale led to seemingly arbitrary length extrapolation: as long as the sequence fit within [0, L], there did not seem to be a limit on the sequence lengths I could use.
Other Takeaways
EOS Token
Does not seem to be much of a contributor. That, or its effects are overshadowed by other length cues (which is already common for instruction fine-tuned models).
We find that the -EOS+Oracle models consistently outperform +EOS+Oracle models across all length splits [on SCAN]. We also observe that after including sequences up to length 26, the models have seen enough of the new template to perform with accuracy ≥ 80% on the rest of the long sequences. However, the question of what the -EOS model is doing that allows it to succeed remains. The +EOS model fails in the non-oracle setting by predicting that sequences should end before they do, and the +EOS+Oracle model fails because once it decodes past its maximum training sequence length, it tends to either repeat the last token produced or emit unrelated tokens. The -EOS+Oracle model succeeds, however, by repeating the last few tokens when necessary, so as to complete the last portion of a thrice command for example.
Yet later,
We find that there is very little difference between the +EOS and -EOS models’ performance on [WMT2009 German to English translation] out-of-domain lengths compared to SCAN, and while -EOS perform better in out-of-domain settings more often than +EOS models, removing the EOS token does not conclusively help with extrapolation. […] We speculate that we do not see the -EOS models consistently outperforming the +EOS ones because are likely more subtle indicators of length that models in both conditions pick up on, rendering the presence of EOS tokens less relevant.
Additionally, in Chowdhury & Caragea 2023,
On the EOS problem: The EOS token is a special marker that a model needs to generate to signify the end of sequence. In similar contexts, some prior works have tried to make the evaluation less stringent (Dubois et al., 2020; Newman et al., 2020) by terminating the model generation based on the oracle EOS position or by truncating oracle sequence based on predicted EOS position. We do not modify the evaluation in any such non-standard manner. Generally, we do not find EOS prediction to be a problem. If the inductive bias is suitable for the task, our models learn to generalize near perfectly without us needing to incorporate any separate mechanism to predict EOS properly.
Random Padding in other NNs
Yang et al. 2023 demonstrates random padding consistently improving feature learning in CNNs.
No Positional Encoding
However, Lasri et al. 2022 demonstrate that this does not work in the case of masked language modeling
Model Context Overcapacity?
I was able to find this Reddit thread, in which (presumably) @lucidrains comments:
it is important for everyone to know that there may be a capacity limit to the context length, as explored by this paper. gpt4 may not have this limit, but smaller variants like llama may. it also depends on the task you are trying to solve. you cannot just get ‘infinite context’, as some would sell you that their network can do. more research needed… hopefully pytorch 2.0 leads to that
Thanks for that paper; I came across it a while ago but have not read it yet. Is the limit due to number of model parameters or size of embedding. I suspect size of embedding to be the biggest factor in limiting how big the context can be.
yea, literature is scant and all over the place in the efficient attention field. in this paper, i believe they claim it is query-key dimension (d_dot), but i think it should depend on the number of heads too. i don’t know of any other papers that explore this topic. i just don’t want people to be surprised if they fine tune to greater context lengths and things don’t work as well as gpt4
Although, when I read that paper I didn’t feel the same way. As in, I didn’t feel the current architecture should lock users into only 2048 sequence length. I believe this is the relevant part for his answer:
Endlessly adding new associations to a memory of finite size, as in Eq. 17, inevitably will reach a limit. In linear attention, information is stored in a matrix and is retrieved using matrix multiplication (see Eq. 19). As a consequence, to prevent associations from interfering with each other upon retrieval, the respective keys need to be orthogonal. Otherwise, the dot product will attend to more than one key and return a linear combination of values. With keys embedded in a ddot space, there cannot be more than ddot orthogonal vectors. That is, storing more than ddot associations will result in a retrieval error. In linear Transformers, when the length of the sequence is longer than ddot, the model might be in such an overcapacity regime.
[…]
Sec. 4.1 argues that the linear Transformers can end up in an overcapacity regime, if the sequence length L exceeds the dimension ddot of the keys. Once in overcapacity, an ideal memory model should dynamically interact with the memory contents and selectively determine which associations to remember or to forget. This is in stark contrast to the standard Transformer which stores immutable pairs of key and value vectors by concatenation, thus increasing the storage size. While such models work well in practice, we consider a model’s capability to update previously acquired knowledge to be critical for many problems. Hence, from the perspective of dynamic interaction with the memory, the purely additive update rule of Eqs. 17 may be sub-optimal.
From this, I get the impression the authors would agree with the above papers. Additionally, the paper admits that their improved algorithm follows the core idea proposed in Anil, which is that by teaching the model to ignore certain tokens, the performance improves.
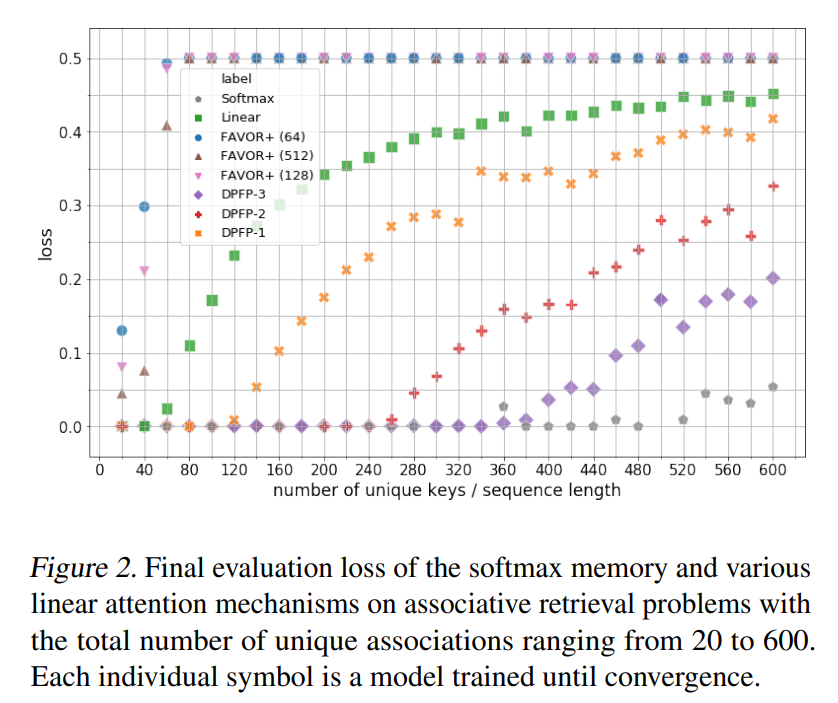 |
|---|
| Softmax still performs the best on retrieval |
Iterative vs. 1-shot feedback
Recall Bueno et al.’s findings on length generalization. More interestingly, we see some remnants of this approach as far back as OpenAI’s GSM8K paper, in which they significantly improve performance on their GSM8K tasks by adding a token-level verifier. In a sense, the use of markup tokens is somewhat similar to a token-level verifier, as it provides the generator with valuable signal after each reasoning step, shifting the probabilities for further steps. While the verifier used in the paper is separate from the generator, the authors note it could be combined. Maybe we don’t need an entirely separate model, or even a score as the feedback from the verification step? Maybe just the prescence of a distinct feedback on the completion of the step is needed?
We can either train verifiers to make a single scalar prediction conditioned on the entire generated solution, or to make a scalar prediction after each token in the solution. By default, we choose the latter, training verifiers to make predictions after each token. This can be viewed as a token-level value function. We compare these two methods in Figure 6a, respectively labeled “solutionlevel” and “token-level”. Predicting the value function at every token is a more challenging and noisier task than judging only the full completion. However, despite the initially slower training, the token-level verifier ultimately outperforms the solution-level verifier. Moreover, the token-level verifier is still improving late in training, whereas the solution-level verifier quickly shows signs of overfitting. We hypothesize that the full value function provides a useful auxiliary signal that encourages the model to judge the reasoning throughout solutions, rather than merely memorizing the correct final answer.
Ironically, OpenAI themselves seem to confirm this with Lightman et al. 2023
To train more reliable models, we can turn either to outcome supervision, which provides feedback for a final result, or process supervision, which provides feedback for each intermediate reasoning step. Given the importance of training reliable models, and given the high cost of human feedback, it is important to carefully compare the both methods. Recent work has already begun this comparison, but many questions still remain. We conduct our own investigation, finding that process supervision significantly outperforms outcome supervision for training models to solve problems from the challenging MATH dataset. Our process-supervised model solves 78% of problems from a representative subset of the MATH test set. Additionally, we show that active learning significantly improves the efficacy of process supervision.
Jianlin Su’s Blog
I highly recommend reading Jianlin Su’s blog, kexue.fm. Su is the lead author of the paper which introduced rotary position embedding, (RoPE). I found this blog post, which discusses potential solutions for the length extrapolation problem, a little amusing because of the introductory section,
后者通过随机位置扰动增强对位置信号的鲁棒性,理论上有可能保留全局依赖,但该方法只适用于Encoder模型,不适合于GPT之类的自回归生成模型。 Machine Translated: The latter enhances the robustness to position signals through random position perturbation, and it is theoretically possible to retain global dependence, but this method is only applicable to the Encoder model, not suitable for autoregressive generative models such as GPT.
Less than a month later, Ruoss et al. propose random position encoding (which can be applied to RoPE). I hope Su makes a blog post discussing it eventually and providing their thoughts. (As of 6/23/2023, I saw he did indeed make a response to it: https://kexue.fm/archives/9603)
Su 2023 proposes a way of using windowed-attention + RoPE, but only on the first L-1 layers. The Lth layer uses standard “full” attention and no RoPE (as the model would not have been trained on the extrapolated lengths) and has a scaling factor of log(n) on the softmax weights. The results are demonstrated using the Gated Attention Unit from Hua et al. 2022, but it can be used with any attention variant. Additionally, a window size of 16 is used, and the following caveats are noted:
- If Window Attention does not add RoPE, the interpolation and extrapolation effects will decrease;
- With Full Attention plus RoPE, the extrapolation effect will decrease;
- Full Attention is not using
log(n)factor, the extrapolation effect will decrease;- If Window Attention is fully used, the interpolation and extrapolation effects will decrease;
- Change the Layer Window Attention to stop at
L-2layers + 2 layers of Full Attention, the extrapolation effect will decrease;w=32(at this time(w−1)(L−1)>N), the extrapolation effect will decrease.
Additionally, Su mentions the Hybrid Window Full Attention is only tested in GAU, but I thought I would mention it any way for posterity. Further testing still needs to be conducted.**
Davis Blalock’s Newsletter
Every week, Davis Blalock reviews the arXiv papers for that week, I found his summaries very helpful for highlighting interesting papers. I only found out this exists after trying to do more digging on random positional encodings, but since discovering, I’m looking forward to more of his previews.
ReLU over softmax
For ReLU conversion, I observed the same problem, in that the model does not converge. I encourage you to read the paper further to build intuition, as in:
However, there still exists a difference in the choice of activation functions, where the FFN usually adopts ReLU and the key-value memory uses Softmax, which may lead to different model performance. In this paper, we will explore the connections between FFN and key-value memory by studying the ReLU and Softmax.
[…]
We conjecture the reason is the exponential normalization in Softmax. Concretely, since Softmax provides the exponential normalization on the elements while ReLU does not, Softmax provides over-centralized distribution over elements, which means only a few elements are highlighted while occupying most weights. Then when the memory size is large, Softmax will overlook most value slots and only utilize a few of them, which does not benefit from the large size of memory. In contrast, there is no competition among elements in ReLU, which is able to aggregate more knowledge. A straightforward method to alleviate this problem is to increase the temperature in Softmax to flatten the output distribution. However, we empirically find it has little effect in experiments.
*Sandwich released on the same day as XPos!
† I meant *my* context, not the model’s; that part was actually easy in comparison
**Call me a Su shill if you want, idc :)
Citations
Updated: 6/25/2023
I did not add an explicit citation section, but I will summarize the influential and orthogonal papers that I have stumbled on and provide citations for them here. Thanks to all the amazing researchers, as without all the disparate insights, this wouldn’t have been possible :)
If you have related work that I did not mention here, feel free to contact me at kaiokendev1@gmail.com with a link to the paper and it’s relevance and I will be happy to add it. I could not possibly have read every paper on the topics, and the solution was only influenced by a small selection, so bear with me.
The Problem of Length Generalization
This section cites papers revolving around the problem of length generalization and potential factors that could lead to Transformer models not being able to length extrapolate well.
Anil et al. 2022 demonstrated that several fine-tuning approaches fail to resolve common length generalization pathologies. They perform a comprehensive study and determine several ways in which this problem manifests.
@article{Anil2022ExploringLG,
title={Exploring Length Generalization in Large Language Models},
author={Cem Anil and Yuhuai Wu and Anders Andreassen and Aitor Lewkowycz and Vedant Misra and Vinay Venkatesh Ramasesh and Ambrose Slone and Guy Gur-Ari and Ethan Dyer and Behnam Neyshabur},
journal={ArXiv},
year={2022},
volume={abs/2207.04901}
}
Chi et al. 2022 analyze ALiBi and find a link to windowed attention, highlighting benefits attained by constricting the receptive field of the model. They employ these learnings to create SANDWICH.
@inproceedings{Chi2022DissectingTL,
title={Dissecting Transformer Length Extrapolation via the Lens of Receptive Field Analysis},
author={Ta-Chung Chi and Ting-Han Fan and Alex Rudnicky and Peter J. Ramadge},
year={2022}
}
Tao et al. 2023 find that rear position embeddings are updated more infrequently than front position embeddings. They propose adding random padding to various patches of the sequence to improve length generalization for BERT models.
@article{Tao2023AFE,
title={A Frustratingly Easy Improvement for Position Embeddings via Random Padding},
author={Mingxu Tao and Yansong Feng and Dongyan Zhao},
journal={ArXiv},
year={2023},
volume={abs/2305.04859}
}
Press et al. 2021 suggest that Transformer models may overfit to specific position embeddings seen during training, even with RoPE. They propose ALiBi in which they add fixed slopes to the QK dot-product to add a decaying token bias which helps long-range sequences and extrapolation.
@article{Press2021TrainST,
title={Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation},
author={Ofir Press and Noah A. Smith and Mike Lewis},
journal={ArXiv},
year={2021},
volume={abs/2108.12409}
}
Liu et al. 2023 observe that large language models exhibit catastrophic glitches in long range language modeling tasks. They perform ablations across several thousand model architectures. One potential cause they list is minor fluctuations in low-level attention head logits.
@article{Liu2023ExposingAG,
title={Exposing Attention Glitches with Flip-Flop Language Modeling},
author={Bingbin Liu and Jordan T. Ash and Surbhi Goel and Akshay Krishnamurthy and Cyril Zhang},
journal={ArXiv},
year={2023},
volume={abs/2306.00946}
}
Length Generalization Solutions
The following section cites papers that propose solutions to length generalization
Chi et al. 2022 has been cited in the section above
Tao et al. 2023 has been cited in the section above
Press et al. 2021 has been cited in the section above
Bueno et al. 2022 showcase that adding markup tokens can help models keep track of their chain of thought over long sequences.
@article{Bueno2022InducedNL,
title={Induced Natural Language Rationales and Interleaved Markup Tokens Enable Extrapolation in Large Language Models},
author={Mirelle Candida Bueno and Carlos Gemmel and Jeffrey Stephen Dalton and Roberto de Alencar Lotufo and Rodrigo Nogueira},
journal={ArXiv},
year={2022},
volume={abs/2208.11445}
}
Mohtashami et al. 2023 employ landmark tokens, a modified grouped softmax attention, and positional jumping to fine-tune a LLaMa model to 32k tokens.
@article{Mohtashami2023LandmarkAR,
title={Landmark Attention: Random-Access Infinite Context Length for Transformers},
author={Amirkeivan Mohtashami and Martin Jaggi},
journal={ArXiv},
year={2023},
volume={abs/2305.16300}
}
Permutated Positional Embeddings
This section cites papers that leverage the technique of shifting or permuting the position embeddings in some way to achieve length extrapolation
Ruoss et al. 2023 propose randomized positional encodings which re-assigns position IDs to a random sequential sequence (that is not necessarily contiguous) greater than the actual sequence length in order to simulate a longer training sequence.
@article{Ruoss2023RandomizedPE,
title={Randomized Positional Encodings Boost Length Generalization of Transformers},
author={Anian Ruoss and Gr'egoire Del'etang and Tim Genewein and Jordi Grau-Moya and R. Csord{\'a}s and Mehdi Abbana Bennani and Shane Legg and Joel Veness},
journal={ArXiv},
year={2023},
volume={abs/2305.16843}
}
Likhomanenko et al. 2021 also propose CAPE (continuous augmented positional embeddings) for applying a random global offset and scale as well local offset to absolute positional embeddings to teach the model the relative information.
@inproceedings{Likhomanenko2021CAPEER,
title={CAPE: Encoding Relative Positions with Continuous Augmented Positional Embeddings},
author={Tatiana Likhomanenko and Qiantong Xu and Ronan Collobert and Gabriel Synnaeve and Alexey Rogozhnikov},
booktitle={Neural Information Processing Systems},
year={2021}
}
Kiyono et al. 2021 proposed SHAPE (Shifted Absolute Position Embedding) which shifts the positions randomly during training to prevent over-fitting on the positions and encourage the learning of the relative information.
@inproceedings{kiyono-etal-2021-shape,
title = "{SHAPE}: {S}hifted Absolute Position Embedding for Transformers",
author = "Kiyono, Shun and
Kobayashi, Sosuke and
Suzuki, Jun and
Inui, Kentaro",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.266",
doi = "10.18653/v1/2021.emnlp-main.266",
pages = "3309--3321",
abstract = "Position representation is crucial for building position-aware representations in Transformers. Existing position representations suffer from a lack of generalization to test data with unseen lengths or high computational cost. We investigate shifted absolute position embedding (SHAPE) to address both issues. The basic idea of SHAPE is to achieve shift invariance, which is a key property of recent successful position representations, by randomly shifting absolute positions during training. We demonstrate that SHAPE is empirically comparable to its counterpart while being simpler and faster.",
}
Attention Calculations
The following papers revolve around the impact of changing the attention calculation on length extrapolation
Chiang and Cholak 2022 mention that scaling the softmax attention logits by log(n), where n is the sequence length, they achieve better extrapolation on the FIRST task.
@inproceedings{Chiang2022OvercomingAT,
title={Overcoming a Theoretical Limitation of Self-Attention},
author={David Chiang and Peter A. Cholak},
booktitle={Annual Meeting of the Association for Computational Linguistics},
year={2022}
}
Shen et al. 2023 propose replacing softmax with ReLU to fix a saturation problem and provide better variance when there are many key-values
@article{Shen2023ASO,
title={A Study on ReLU and Softmax in Transformer},
author={Kai Shen and Junliang Guo and Xuejiao Tan and Siliang Tang and Rui Wang and Jiang Bian},
journal={ArXiv},
year={2023},
volume={abs/2302.06461}
}